My Topic
As a PhD student, it’s quite common to have conversations where people ask what I’m researching. This is always a complex question for anyone doing a PhD because the actual topic is often so far removed from anything recognisable for someone not in the field that it’s a struggle to know where to begin.
But here’s my attempt.
tldr
AI models (particularly vision-based ones) are massively insecure. There is about a decade of work which demonstrates how ‘adversarial attacks’ can be used to invisibly manipulate an image1, causing the AI model to misclassify it even though it looks completely unchanged to the human eye. Here’s an example:
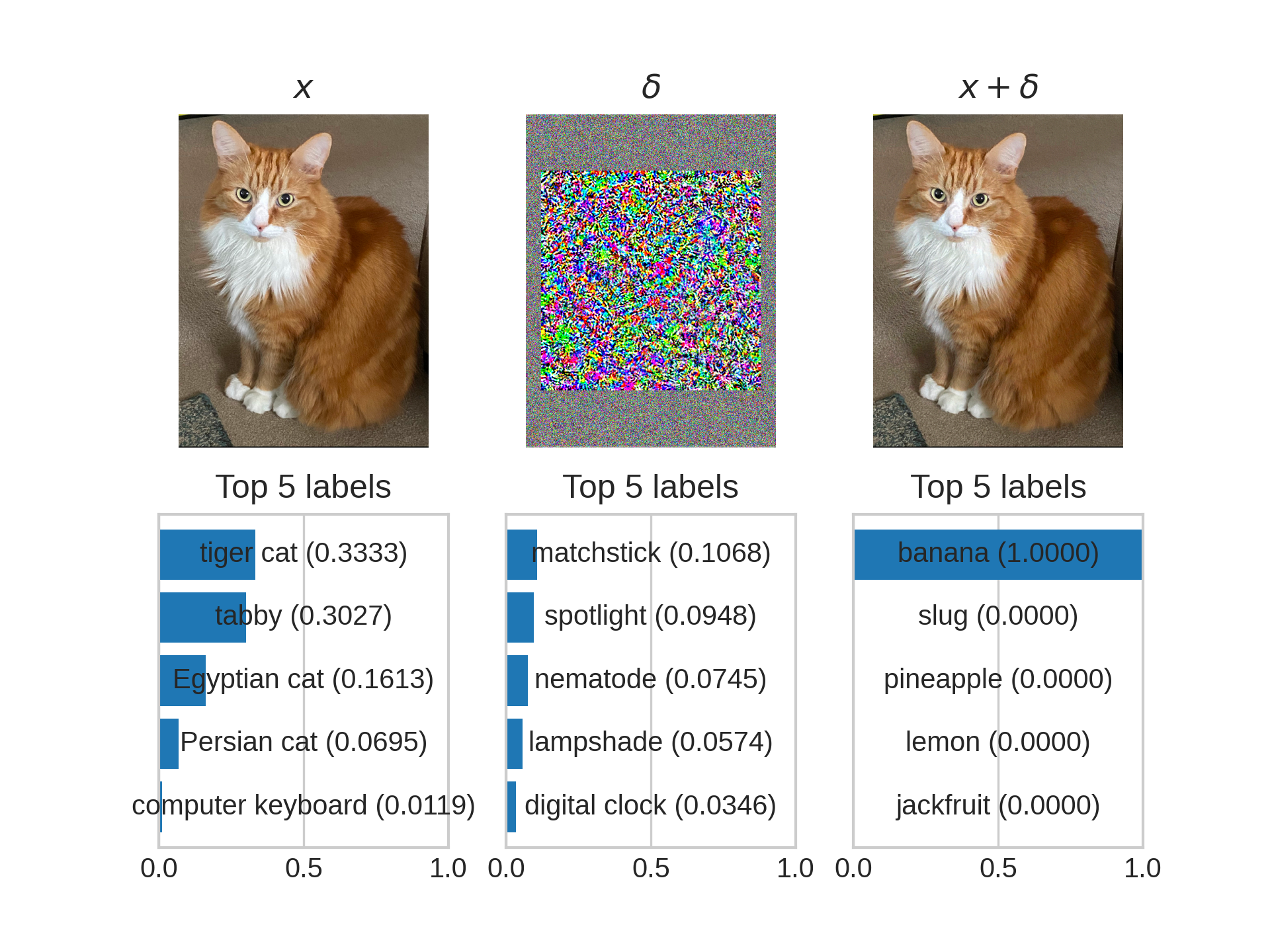
In terms of security, this is a big issue! This impacts things like facial recognition models (there have been real-world implementations of these adversarial attacks), autonomous vehicles2, and generally, any scenario where an image will be passed to an AI model with some classification being performed. This is not only a security issue, but it also indicates that our understanding of how AI models work is not as correct as we first thought. This starts getting into longer arguments regarding model interpretability (which is a super important and relevant area, especially now with LLMs), which we’ll handle another time.
-
Szegedy et al. 2014 “Intriguing properties of neural networks” ↩
-
Kurakin et al. 2018 “Adversarial examples in the physical world” ↩